最近在看逻辑英语的课程,感觉还挺不错的,不过看完视频好像啥也没记住😥,正好看见有逻辑英语的纸质书就买了一本没事可以翻翻,这本书随书赠送了一些配套的音频,但是都是一个一个的分开在微信公众号文章内的,想要下载下来听比较方便一些,所以研究了一下,花了十几分钟写了个小爬虫,趁着有空写篇博客记录一下。
1. 网页分析
首先我们打开音频的汇总页面,看一下这个页面的HTML结构。
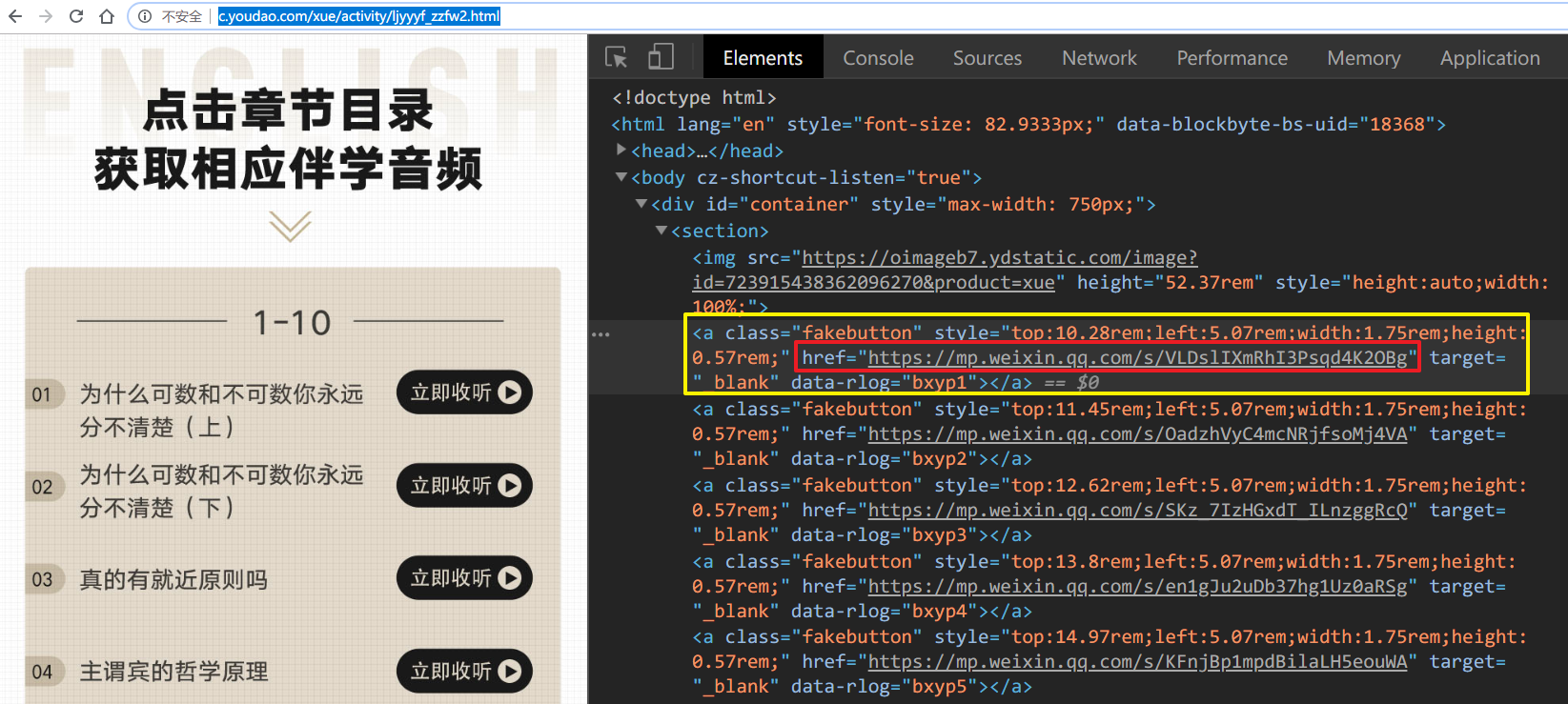 可以看到每一个音频都指向一个公众号图文网页,只需要获取这些
可以看到每一个音频都指向一个公众号图文网页,只需要获取这些href的链接就可以进去音频的页面了。
接下来我们进入图文页面,看看怎么获取音频文件。
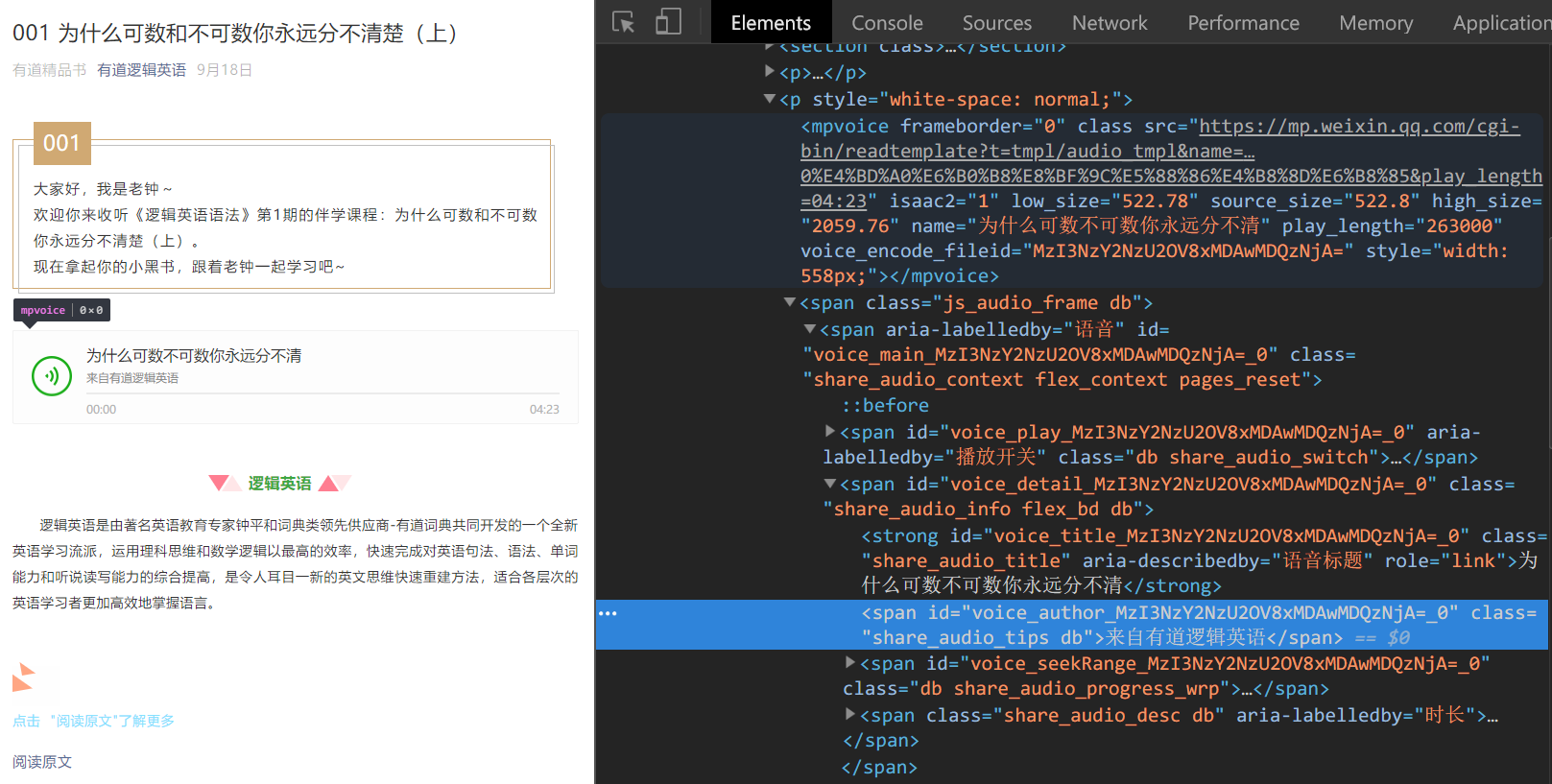
在音频页面找了一下,没有发现有音频文件的,也没有找到<audio>标签,但是发现有一个不认识的标签mpvoice,看起来像是微信自己弄的一个标签,看来从页面上不能直接获取音频文件了。
先不管HTML代码了,点击播放按钮看一下是怎么播放的。
没有发现什么有价值的东西,先放弃分析HTML了,看看Network中有什么有用的东西,点完之后果然有收获。
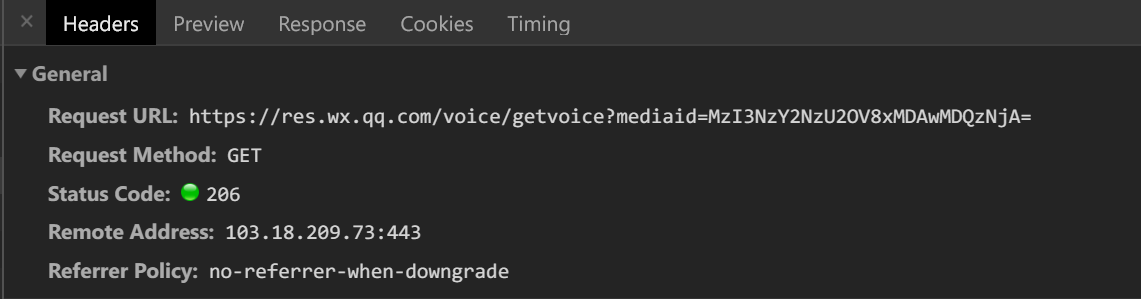
看这个接口大概就可以猜到是获取音频的,复制链接在新窗口打开,果真是音频文件。在打开几个音频图文,可以发现每个音频调用的都是相同的接口,唯一的区别就是查询参数mediaid的值不同,由此可以知道微信图文获取音频是调用该接口,带上音频的一个id就可以获取。
接下来就是找找mediaid在哪里了,打开HTML代码,很容易就发现了在<mpvoice>标签上有一个voice_encode_fileid属性的值就是mediaid的值。
分析完了页面的结构,接下来就很容易写代码了。
2. 代码编写
使用Go语言写简单的爬虫很快,先说几个关键点,然后贴完整的代码。
代码使用了github.com/PuerkitoBio/goquery这个库解析HTML结构的,如果你熟悉JQuery的使用,那么可以很容易的使用这个库解析HTML获取有用的数据。
|
|
- 首先使用
NewDocumentFromReader函数将获取的页面HTML字符串,转换成goquery中的Document结构,Document中包含的Node可以由选择器语法进行解析。
|
|
- 使用
Find函数获取HTML中的指定Node,指定的方式是跟使用Jquery一样的,例如这里我们查找section标签下的a标签。 - 由于
a标签是有很多个的,所以这里使用Each函数处理每一个节点。 - 然后在循环中,获取每一个
a标签的href属性的值。获取节点属性的值有两个方法:AttrOr("",""):第一个参数是属性的名字,第二个参数是没有找到指定的属性时,默认返回的值。Attr(""):这个方法如果没有找到指定的属性,就会返回string和bool类型的零值,否则就返回指定属性的值和true。
完整的代码:
|
|