
1. 什么时候使用MQ
1.1. 什么是MQ?
- 消息队列(Message Queue)是一种跨进程的通信机制,用于上下游传递消息。
- 使用MQ,消息发送上只需要依赖MQ,逻辑上和物理上都不需要依赖其他的服务,对业务进行了解耦,消息上下游互相不依赖,只需要知道MQ的存在即可。
- MQ的不足之处:
- 多了一个MQ组件,使系统更加复杂。
- 消息的传递延时会增加(队列处理)
- 消息可靠性和重复性互为矛盾(消息丢失后难以保证下次是否会重复执行该消息)
- 下游无法知道上游的执行结果(上下游完全解耦,没有互相调用)
1.2. 什么时候不使用MQ
- 调用者实时依赖执行结果的业务场景,不适合使用MQ,也就是如果我们的业务中有某个方法需要获得一个返回结果才能继续执行的场景下,不适合使用MQ,因为MQ是一个队列执行的,延迟无法避免。
1.3. 什么时候使用MQ
- 场景一:数据驱动的任务依赖
- 调用者不需要实时获取返回结果时,可以使用MQ,订阅返回消息即可,受到消息再做下一步处理,不需要实时处理。
- 场景二:上游不关心执行结果
- 上游执行输出后,不在关心该输出后续的业务,这时可以使用MQ。
- 场景三:上游关注执行结果,但执行时间很长
- 上游关注下游的执行结果,但是下游可能执行时间很长,这时候可以使用MQ,上游调用下游后,在MQ中订阅下游执行的结果,这需要一个跟前面场景颠倒的顺序:上游订阅消息,下游发送消息。
2. 使用MQ削峰填谷,防止流量冲击
- 使用直接调用(RPC)会出现的问题:
- 上下游业务不一致,复杂性不一致,可能导致一方“无事可做”,另一方系统被流量压垮。
- 例如秒杀场景下,上游负责用户下单,下游负责处理订单、检查库存等等,这是就出现流量不平衡的问题,需要借助MQ实现“削峰填谷”。
- MQ的能力:
- 上游将消息发送给MQ,不用管下游的处理情况。
- 下游根据自身的能力,依次从MQ中读取消息进行处理即可,不会造成下游处理压力。
- 问题:
- 由于MQ作为中间介质的存在,会受到上下游两方的影响,上游发送消息过多、下游处理任务能力不足,都会导致MQ中的消息堆积,造成延迟、超时,这时候我们不能依靠MQ的能力,尽量做好上下游业务的优化,尤其是复杂一方的处理能力,这才是本质。
3. MQ能否实现消息必达
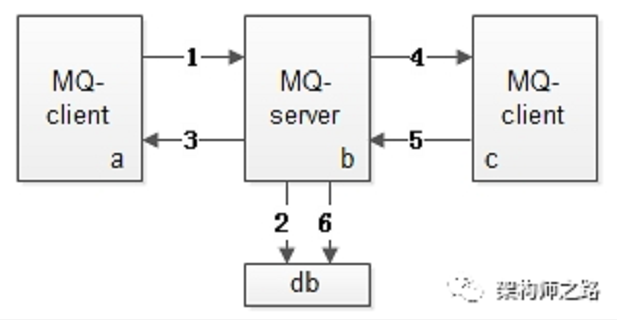
核心的两点:
- 消息落地
- 发布者(上图1-3):
- MQ-Client发送消息给MQ-Server(发送消息)
- MQ-Server将消息落地(保存到数据库)
- MQ-Server将应答发(是否落地成功)送给MQ-Client(回调)
- 订阅者(上图4-6):
- MQ-Server将消息发送给MQ-Client(回调)
- MQ-Client回复消息给MQ-Service(发送消息,是否执行完)
- MQ-Server收到
ack,将之前落地的消息删除(从数据库删除)
- 发布者(上图1-3):
- 消息超时重传、确认
- 发布者(上图1-3):
- 一旦超时或丢失,MQ-Client定时器重发消息,直到收到回调消息,发次重发仍然未收到回调消息,则通知回调接口发送失败。
- 订阅者(上图4-6):
- 一旦超时或丢失,MQ-Server定时器重发消息,直到收到
ack,并且落地消息已经删除完成。
- 一旦超时或丢失,MQ-Server定时器重发消息,直到收到
- 发布者(上图1-3):
- 消息落地
消息必达伴随着可能发生的消息重复
消息必达会增加IO操作,影响一些效率,必须权衡信息的可靠性和性能。
保证消息的幂等性,可是从客户端对每条消息生成一个
msg-id,在发布者订阅者和MQ之间传递,以保证相同的消息只落地一次,只执行一次。
4. 使用MQ实现“延时消息”
延时消息相当于一个定时任务。
普通定时任务轮询的不足: - 轮询效率低 - 每次需要扫库,多余数据增加计算负担。 - 轮询频率不好控制,频率太高计算负担太大,频率太低时间误差无法保证。 高效延时消息的实现案例:环形队列
|
|
一个简单的实现:
- 在MQ中应该有这么一个环形队列(数组),例如有3600长度(代表3600秒)。
- 收到的需要延时的任务,都一次加入这个队列中,在加入时需要一些处理:
- 首先根据任务延时的时长计算出任务在环形队列中的圈数,然后根据余数,将该任务插入队列中具体的索引处。
- 将任务的执行封装起来,这里留一个简单的调用标识(例如存储一个方法的指针),这样在执行到的时候,可以拿出来交给另一个线程去执行,避免影响队列的下一步轮询。
- 创建一个
Timer每秒向前执行一次判断,拿出其中保存的Task,判断Task的属性Cycle_Num是否等于0,等于0就应当立即去执行这个Task,不等于0,就将Cycle_Num减1,表示这轮扫描已经结束。
以上是根据沈剑老师讲解的案例写的简单例子,看评论里面有很多读者提出Redis等开源组件有实现延迟消息功能,可以酌情使用,懂得底层实现总是好的。
*参考58沈剑公众号系列文章。*